接續 Day 8
延續前一天講的 log-structure,其中我們在意的是相同 key 的資料順序要對,如此才能知道哪筆資料是新的嘛,所以在每個 segment log 中,key 之間的排序不是太重要的事,我們可以為此來嘗試做個小小改變:對 key 做排序,
我們稱這個為 Sorted String Table (寫短點為 SSTables ),這裡我們要求每個 key 只會在該 segment 檔案出現一次 (前一天講的壓實 (compaction) 作業可以保證這點),SStables 比 segment log 加 Hash Index 有以下幾個優點:
使用合併排序演算法合併 segment 檔案簡單有效率,就算檔案比可用記憶大時也是如此,如下示意圖,首先從每個檔案讀一個 key 的資料,然後在選擇最小的 key 寫出到檔案裡,再來就從該 segment 讀下一個 key 進來,以此類推,如圖中綠色數字的順序,結束後,合併後的 segment 檔案也是經過排序的,因為原來的 segment 檔案也是有排序。

不用擔心遇到一樣的 key 時該怎麼辦,若我們合併相鄰的 segment,則我們就會知道哪個 segment 是最新的,就能留下最新的資料,如果圖上第 3 次選到的 key 一樣。
在 Index 表格裡你不用保留所有 key 的 byte offset (偏移),如下圖,假設你要找 key 為 handiwork 的資料,從 index 表格就可曉得 handiwork 在 handbag 和 handsome 之間 (因為資料已經過排序),然後就從這區間找資料。

能做到範圍搜尋,這裡也可以選擇你不同的儲存策略,把特定範圍的資料當成一個 shard 區域儲存,如此每一個 index 對應到的區塊都是緊密的資料,就能節省硬碟空間也能減少 I/O 頻寬使用。
你或許會想,我們怎麼排序各 segment 裡的資料?
首先我們會先把資料寫到記憶體裡,然後記憶體內的資料結構會使用 red-black 樹或 AVL 樹,如此就能確保在新增資料後時有排序的,詳細步驟如下:
當資料庫又掛掉時,memtable 中的資料就會消失,這看起來挺嚴重的,但是我們可以用前一天講到的 log 機制來保留 memtable 中的資料,這個 log 不需要排序,就只是 append-only ,其目的就是確認資料庫掛掉重啟時,我們 memtable 中的資料不會遺失。
上面提到的這個機制已經實做在 LevelDB 和 RocksDB 中,類似的儲存引擎 (storage engine) 也使用在 Cassandra 和 HBase 裡,這 2 個都是啟發自 Google 的 BigTable 論文,起初,這個 indexing 結構是 Patrick O’Neil 提出的 論文 ,將此結構稱為 Log-Structured Merge-Tree (或 LSM-Tree),建立在前一天講到的 log-structure 架構下,這種 storage engine 稱為 LSM storage engine。
Lucene 和 Elasticsearch 也是用類似的方法儲存他們的 term dictionary,完整的字串 index 比 key-value index 複雜的多但概念差不多,把 term 當 key 用就好了,value 就存 document id,一樣在背景會有 segment merge。
LSM-Tree 最慘的情況就是 key 不存在,因為我們要找所有的 SSTables,針對這點,storage engine 會又再新增另一個額外的資料叫 Bloom Filter,這個在記憶中的資料會告訴你,你要找的 key 是否存在在這個資料庫中。
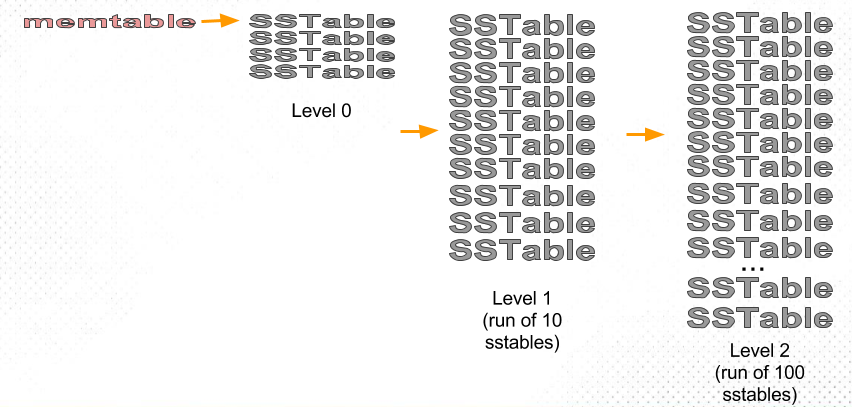
接下來要簡單介紹 2 種不同的 SSTable compaction 和合併策略,size-tiered 和 leveled,LevelDB 和 RocksDB 使用 leveled,HBase 使用 size-tiered,Cassandra 2 種都支援,
size-tiered compaction 是把比較新和比較小的 SSTable 合併到較老和較大的 SSTable,
leveled compaction 則是把 SSTable 分多個 level,level 0 會與 level 1 一起做 compaction,當 level 1 超過某個 SSTable 大小後,挑一個與 level 2 做 compaction,以此類推。
SSTable 完美的解決了前一天講的 Hash index 的 2 個限制,compaction 用合併演算法簡單有效率,又能做到範圍查詢,因為是寫連續型的資料進硬碟,所以 LSM-Tree 的吞吐量也很高,在 ETtoday 數據系統下,當流量因為某些新聞事件飆高時,Cassandra 是幾個少數我們不用太擔心的服務,P99 都在 2,3 ms 以內,這都是歸功於 LSM-Tree 啊!
明天會繼續講 B-Tree。

